
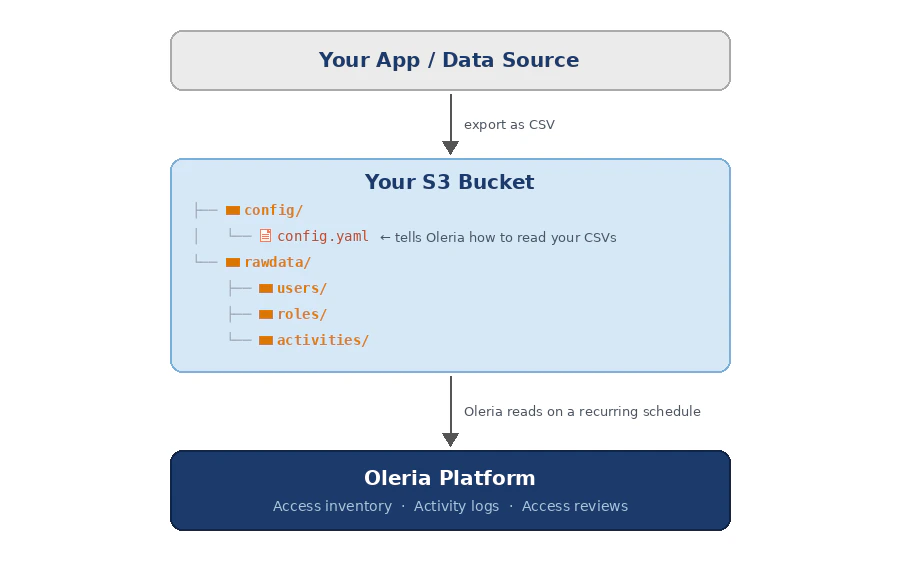
How it works
Prerequisites
- An Amazon S3 bucket in your AWS account where you will upload your data.
- AWS IAM admin access to add a bucket policy to that S3 bucket.
- Your application’s data exported as CSV files (comma-separated values with a header row).
Use a dedicated S3 bucket or a scoped prefix within your bucket for Oleria data to limit access to only what is needed.
Set Up Your S3 Bucket
1
Create or identify your S3 bucket
Create or identify the S3 bucket you will use to share data with Oleria.
2
Organize your files
Organize your files inside the bucket using the following folder structure: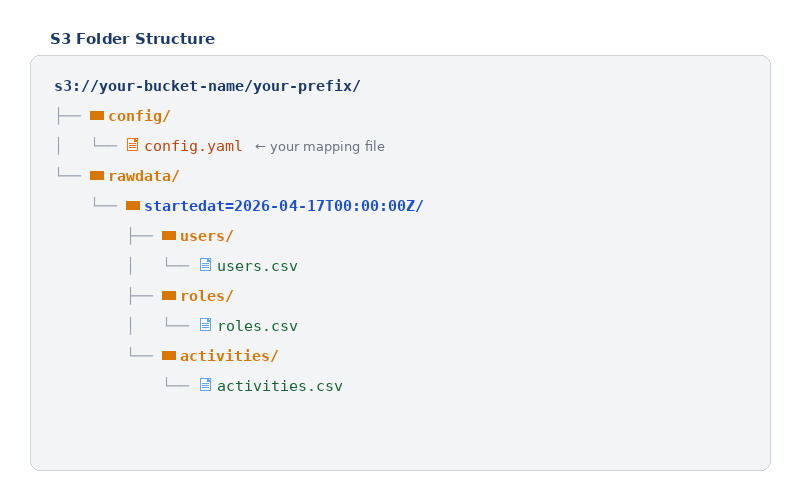
The
config/ folder must contain exactly one .yaml file - Oleria discovers it automatically. The date-stamped folder under rawdata/ (e.g. startedat=2026-04-17T00:00:00Z) tells Oleria which data is new. Each time you export fresh data, create a new folder with the current timestamp. Oleria always picks the most recent one. If your data does not change frequently, you can place your CSV subfolders directly inside rawdata/ without a date-stamped folder.Prepare Your CSV Files
Your CSV files must have a header row. The column names in the header are what you reference in theconfig.yaml file. Column names can be anything - you map them to Oleria’s fields in the config.
Example users.csv:
roles.csv:
user_roles.csv (membership - which user has which role):
Create Your config.yaml
Theconfig/config.yaml file maps your CSV columns to Oleria’s data model. Your Oleria Customer Success team can provide a starting config based on your data, or you can write it yourself using the format below.
Oleria will soon provide an automated way to analyze your CSV data and generate the
config.yaml for you - no manual authoring required. Coming soon.What object types can I map to?
Entity objects - use these for things like users, roles, and groups:
Relationship objects - connect two entities together. Always use the
links shorthand for these:
source.s3 fields
These fields go inside source.s3 in your config.yaml. They tell Oleria where your S3 data lives and how frequently to sync access data and activity logs.
field_mappings vs links
Available fields reference
Available fields reference
applicationaccount and identity - Application & IdP users
role - Roles & permission sets
usergroup - Groups & teams
person - HR person records
employee - HR employee records
department - Departments & org units
activity_analysis - Audit logs & events
application_instance - IdP-managed applications
role - Roles & permission sets
usergroup - Groups & teams
person - HR person records
employee - HR employee records
department - Departments & org units
activity_analysis - Audit logs & events
application_instance - IdP-managed applications
Minimum viable example
The simplest possible config - application users and roles, with a membership relationship:Full example (HR system)
This example models an HR export with employees, departments, and org hierarchy:config.yaml and matching CSV files:
Grant Oleria Access to Your S3 Bucket
Oleria reads your data using a dedicated AWS IAM role. You need to add a bucket policy that allows this role to read your files.1
Get the Oleria IAM role ARN
Your Oleria Customer Success team will provide you with the exact IAM role ARN for your environment. The role follows this format:
2
Add a bucket policy
Go to your S3 bucket in the AWS Console → Permissions tab → Bucket policy → Edit, and paste the following policy. Replace the placeholders with your values and select Save changes.
3
Update the KMS key policy (if applicable)
If your S3 bucket is encrypted with a customer-managed KMS key, update the KMS key policy. Go to AWS KMS → select your key → Key policy → Edit, and add the following statement:
Connect the Integration in Oleria
1
Open the integration
Go to your Oleria workspace, select Integrations → select Custom Application.
2
Complete the connection form
Fill in the connection form that appears:
-
Application Name - a label for this integration in Oleria. Use a name that describes your data source (for example:
Lattice HR,Databricks Prod,Internal App). -
S3 Data Path - the full S3 URL to the root folder of your data. This is the folder that contains your
config/andrawdata/subfolders. Example:s3://your-bucket-name/your-prefix/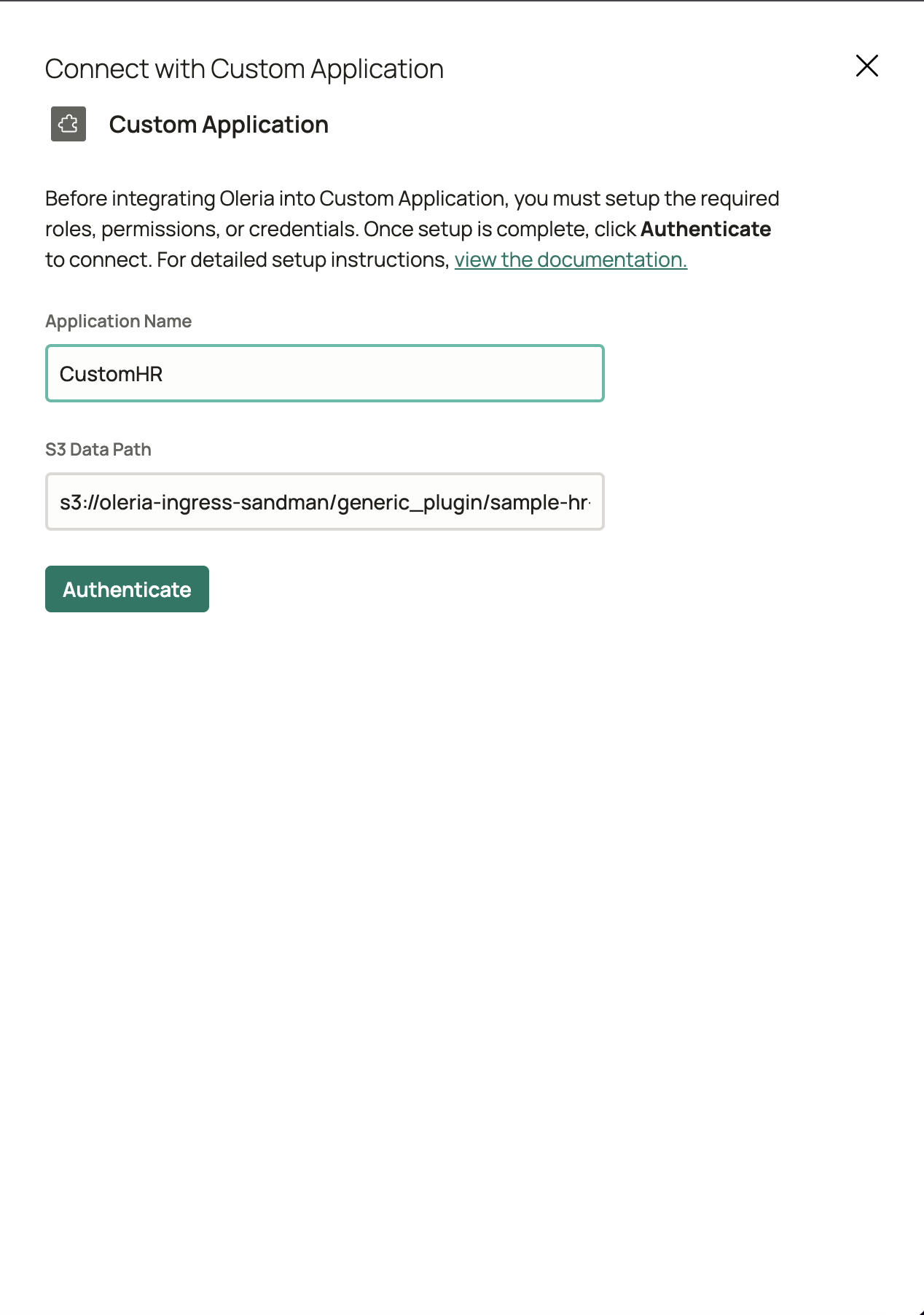
3
Authenticate
Select Authenticate. Oleria will verify it can reach your S3 bucket and read your configuration file.
4
Confirm the connection
Once connected, find your integration in the Connected Integrations section of the Integrations page. Oleria will sync based on the intervals defined in your 
config.yaml - by default, access data every 3 hours and activity logs every 1 hour. You can override these using rbac_sync_interval_hours and activity_sync_interval_hours in your config. Oleria will only process data when new files are available.